The database service rolled out by Amazon last week will prove to be a clunker, despite all the praise it's received. It throws out three decades of experience with SQL and relational databases and demands developers learn more syntax to get less accomplished. It's just cover fire, and pretty intense cover fire at that, demanding a rewrite of the core of your Web application, the model layer.
I don't think Amazon is ill-intentioned, I just think the company made the mistake of thinking a system that works well for Amazon will be useful for the rest of us. The success of the ingenious S3 and EC2 platforms left the company with a surplus of hubris, and God bless them for launching a failure in a market Google and Microsoft don't even know exists. You don't build a market without some stumbles, and Amazon's success in assembling an Internet operating system is stellar so far.
People used to say Google was building an Internet Operating System, but as it turns out they were building Office for the Web. Which is fine. But Amazon is doing something much more empowering, and in the end I think they will have created more value outside their walls than Google ever did, even though they probably won't reap Google-scale profits.
Amazon's success is no small feat. Microsoft has been talking about Web services for years but in the end the two definitions most people heard were "a single sign-on system owned by Microsoft" and "a complicated message interchange system designed to sell copies of Windows Server." Google has crippled virtually every API they have launched. Apple and Yahoo have been focused on a Hollywood vision of the Net (both companies were run by studio chiefs for most of this decade) and are effectively out of this particular business entirely, by choice.
As it turns out, Amazon is not really in the business by choice either. It is in it by necessity. Yes, Amazon surely put some real work into turning S3 and EC2 from internal tools into public utilities. But it built those tools because it needed them -- reliable systems built on easy-to-grok open standards, capable of scaling quickly, just the sort of thing for a company as large and busy as Amazon. As it turns out, once you've built that sort of tool, you're more than halfway toward building something for the entire world.
Again: Amazon built some Web services because it needed them, then realized the rest of us would need them.
Amazon is a company that sells books and a bajillion other things over the Internet. That's what it does. Retail. It is not a software company, not even today, despite EC2 and S3, despite the fact that it has had kick-ass coders since its launched, despite what it may yet become.
Amazon is a user selling the software it made for itself.
This is important. This is new.
Microsoft and Google have always dog-fooded their own software, but that's the exception that proves the rule, which is this: Software companies make software to solve other peoples' problems.
And software companies never understand the problems they are solving as well as they understand the problem of making software.
So now their customers are taking matters into their own hands and building their own software.
This interests me personally because the same thing is happening to my industry, the news media. A reporter will never understand a beat as well as his sources and readers. A chump journalist at a tech magazine or business journal will never be able to write about software as well as Joel Spolsky or Philip Greenspun, who actually make software and actually run businesses. My only consolation is that most programmers -- and most people in any domain -- do not have half the writing talent of a Spolsky or Greenspun, a Graham or Shirky, a Yegge or Wall.
And so it is with software. Most software buyers are utterly lost at the sight of a command line, much less a compilation error.
But we're starting to see some cool users swimming against the tide. Call them babes in userland. An Amazon here. An Adrian Holovaty there. And, back in ancient Web history, a now-defunct online magazine launching the software that served you this page.
Then there are the chumps like me, learning scripting languages and server administration in my spare time, building a random collection of tools, and fervently hoping that Clary Shirky was right.
Sunday, December 16, 2007
Thursday, December 13, 2007
Reconsider the bonds in your 401k
Today I logged in to my 401k account, which I hadn't checked for about a year.
The returns are fine, but when I drilled down into my bond fund on a whim, I was horrified:

See that there "MBS Passthrough," where I have 34 percent of my bond money? Those are Mortgage Backed Securities. And CMBS? That means "Commercial Mortgage-Backed Securities." And CMO? "Collateralized Mortgage Obligations."
In total, nearly 60 percent of my bond money is exposed to the mortgage market. The CMBS and CMO categories are the most worrisome to me, because as I have written and blogged and read (and read and read and read), huge chunks of those markets have turned illiquid. In other words, it is hard to sell these securities, because it is hard to find buyers.
And it is hard to find buyers because people realize the ratings assigned to many bonds by Moody's, S&P and Finch were simply wrong -- there was far more risk hiding in certain types of debt security than was reflected in the ratings.
The short version: the bond market is broken.
And now the government is expected to intervene.
Do you want to be invested in a broken market where, when you go to sell your bonds, it may be impossible to find a buyer? Do you want to be in a market where the government is about to rewrite all the rules?
When you opted to put some of your 401k in bonds, did you do so to increase the risk and volatility in your portfolio, or did you have the opposite in mind?
For most people, the bond portion of the 401k is intended to provide lower risk and volatility than the stock market, along with diversification -- returns not correlated with the stock market. Heavy exposure to mortgage backed securities undermines these goals.
Your bond fund probably looks a lot like mine, since my bond fund is designed to mimmick the entire bond market.
Check your 401k and reevaluate your bond holdings and whether to reduce them.
I personally sold half my bonds, reducing bonds to 15 percent of my 401k.
The returns are fine, but when I drilled down into my bond fund on a whim, I was horrified:

See that there "MBS Passthrough," where I have 34 percent of my bond money? Those are Mortgage Backed Securities. And CMBS? That means "Commercial Mortgage-Backed Securities." And CMO? "Collateralized Mortgage Obligations."
In total, nearly 60 percent of my bond money is exposed to the mortgage market. The CMBS and CMO categories are the most worrisome to me, because as I have written and blogged and read (and read and read and read), huge chunks of those markets have turned illiquid. In other words, it is hard to sell these securities, because it is hard to find buyers.
And it is hard to find buyers because people realize the ratings assigned to many bonds by Moody's, S&P and Finch were simply wrong -- there was far more risk hiding in certain types of debt security than was reflected in the ratings.
The short version: the bond market is broken.
And now the government is expected to intervene.
Do you want to be invested in a broken market where, when you go to sell your bonds, it may be impossible to find a buyer? Do you want to be in a market where the government is about to rewrite all the rules?
When you opted to put some of your 401k in bonds, did you do so to increase the risk and volatility in your portfolio, or did you have the opposite in mind?
For most people, the bond portion of the 401k is intended to provide lower risk and volatility than the stock market, along with diversification -- returns not correlated with the stock market. Heavy exposure to mortgage backed securities undermines these goals.
Your bond fund probably looks a lot like mine, since my bond fund is designed to mimmick the entire bond market.
Check your 401k and reevaluate your bond holdings and whether to reduce them.
I personally sold half my bonds, reducing bonds to 15 percent of my 401k.
Tuesday, December 11, 2007

Sunday, December 09, 2007

Tuesday, December 04, 2007
Sunday, December 02, 2007
Crappy GMail design
Continuing the Weekend of Inane Web Design, GMail has decided email it sends itself must be spam.
Backstory: If you want to be able to send email using an alternate email address in GMail, GMail first sends an email to the alternate address with a link to verify you own the account.
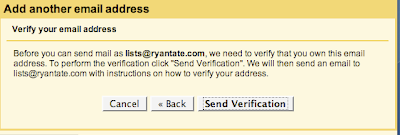
I did this earlier today. My verification email would be coming straight to my GMail account, which receives all messages sent to the alternate address.
I kept waiting, and waiting, and the verification email never came. After about 10 minutes, I checked my spam folder. Guess what GMail thinks is spam? GMail's own administrative emails. Click for the larger version:

I went ahead and opened the message and clicked "Not Spam." That way, you know, they might eventually figure out their own email is not spam, though the miracle of Bayesian technology.
Backstory: If you want to be able to send email using an alternate email address in GMail, GMail first sends an email to the alternate address with a link to verify you own the account.
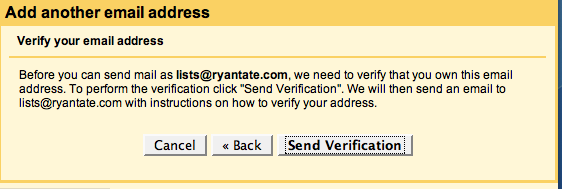
I did this earlier today. My verification email would be coming straight to my GMail account, which receives all messages sent to the alternate address.
I kept waiting, and waiting, and the verification email never came. After about 10 minutes, I checked my spam folder. Guess what GMail thinks is spam? GMail's own administrative emails. Click for the larger version:

I went ahead and opened the message and clicked "Not Spam." That way, you know, they might eventually figure out their own email is not spam, though the miracle of Bayesian technology.
Saturday, December 01, 2007
Crappy Linksys design
Let's say you're trying to join a WEP-encrypted wireless network (despite the security issues), and you need the password in hex format, since plain text passwords often fail to work.
So the dude who runs the network goes to look up the hex password, and sees the following when he connects to his Linksys router in his Web browser:

Oh, cool. The hex password is "6D68E02B33F2BCACC".
But, gee, why can't my MacBook connect to the wireless network? Why isn't the password working?
Because that wasn't really the password. The fool who designed the interface for my Linksys router made the hex password field way too short to show the password!
There are nine password characters hidden by the end of the password field. Here's what the password field would look like if it were designed properly:

The whole hex password is visible here.
This design flaw bit me at Thanksgiving, when our guest could not connect to the network even after I pulled up the hex password via our Linksys router interface. And I suspect it is behind some of the online wireless questions involving Linksys routers and Macs that no one can resolve.
Linksys' design is especially stupid because every single 128-bit (really 104-bit, but whatever) hex password ever used for any WEP connection is the same length: 26 characters. It's just the way the WEP standard works. And Linksys knows this, which is why the HTML form field for the hex password limits you to 26 characters:
 Once you're aware of this issue, it is possible to see the nine hidden characters by carefully manipulating the mouse in the Linksys hex password field and scrolling to the right. But you shouldn't have to do this. The password field should be properly designed to begin with.
Once you're aware of this issue, it is possible to see the nine hidden characters by carefully manipulating the mouse in the Linksys hex password field and scrolling to the right. But you shouldn't have to do this. The password field should be properly designed to begin with.
So the dude who runs the network goes to look up the hex password, and sees the following when he connects to his Linksys router in his Web browser:

Oh, cool. The hex password is "6D68E02B33F2BCACC".
But, gee, why can't my MacBook connect to the wireless network? Why isn't the password working?
Because that wasn't really the password. The fool who designed the interface for my Linksys router made the hex password field way too short to show the password!
There are nine password characters hidden by the end of the password field. Here's what the password field would look like if it were designed properly:

The whole hex password is visible here.
This design flaw bit me at Thanksgiving, when our guest could not connect to the network even after I pulled up the hex password via our Linksys router interface. And I suspect it is behind some of the online wireless questions involving Linksys routers and Macs that no one can resolve.
Linksys' design is especially stupid because every single 128-bit (really 104-bit, but whatever) hex password ever used for any WEP connection is the same length: 26 characters. It's just the way the WEP standard works. And Linksys knows this, which is why the HTML form field for the hex password limits you to 26 characters:
 Once you're aware of this issue, it is possible to see the nine hidden characters by carefully manipulating the mouse in the Linksys hex password field and scrolling to the right. But you shouldn't have to do this. The password field should be properly designed to begin with.
Once you're aware of this issue, it is possible to see the nine hidden characters by carefully manipulating the mouse in the Linksys hex password field and scrolling to the right. But you shouldn't have to do this. The password field should be properly designed to begin with.Monday, November 26, 2007
Update: GMail IMAP import screwy, at least for now
GMail seems to be re-timestamping email messages copied via IMAP, so IMAP is not an ideal way for me to import old Outlook messages, as I had thought. All the old messages appear new in list views and sort new. D'oh.
I added an update to the original item.
Update: Based on a comment from Stephen Foskett and some workarounds/fixes I read about in the GMail Google Group, I am hopeful I can get this working in the next few days. Jamming at work right now, though.
I added an update to the original item.
Update: Based on a comment from Stephen Foskett and some workarounds/fixes I read about in the GMail Google Group, I am hopeful I can get this working in the next few days. Jamming at work right now, though.
We're halfway to RSS replies (in reply to inReplyTo)
This past weekend I posted to this blog the idea of an inReplyTo RSS element to enable all kinds of cool features in feed readers and to civilize discourse on the Web.
Now I realize we're halfway there.
For many, if not most, RSS items, you can figure out what other items are being replied to simply by looking at the links within the body of the item ("description" in RSS or "content" in Atom). Whatever URLs are linked to are what the item is "reply"ing to.
Now I realize we're halfway there.
For many, if not most, RSS items, you can figure out what other items are being replied to simply by looking at the links within the body of the item ("description" in RSS or "content" in Atom). Whatever URLs are linked to are what the item is "reply"ing to.
Someone made Flickr for your MP3s!
So a few weeks ago I publicly yearned for a personal online MP3 locker -- basically Flickr for your music files. I even reserved tunesr.com.
Well, last night Arvin Dang posted in the comments a pointer to LaLa.com that looks almost exactly like what I wanted -- basically the look and feel of iTunes on the Web.

There seems to be one big thing missing, however: a bulk upload tool. When I tried to upload from my new lala.com account, it gave me a file prompt that would only let me select individual files. On the other hand, the stated minimum requirements in the Help section is Mac OS X 10.4, and right now at work I only have 10.3.9. I'll try again at home and see if things are any better under 10.4 (Though most of my files are on Win2k and that's not officially supported ... d'oh.)
Well, last night Arvin Dang posted in the comments a pointer to LaLa.com that looks almost exactly like what I wanted -- basically the look and feel of iTunes on the Web.

There seems to be one big thing missing, however: a bulk upload tool. When I tried to upload from my new lala.com account, it gave me a file prompt that would only let me select individual files. On the other hand, the stated minimum requirements in the Help section is Mac OS X 10.4, and right now at work I only have 10.3.9. I'll try again at home and see if things are any better under 10.4 (Though most of my files are on Win2k and that's not officially supported ... d'oh.)
GMail PST import solution -- sort of.
D'oh! My get-rich-quick scheme has been foiled!
On the (very) bright side, Stephen Foskett, a fellow pack rat, has figured out a way to upload your email archives into GMail that is going to save everyone a lot of time. No installing POP servers, converting to CSV files, or losing your email timestamps-.
You basically just turn on IMAP in Outlook and in GMail, and then copy emails into GMail by dragging and dropping onto the appropriate GMail folder. Uh, pretty simple and elegant. Way to make us look dumb, Stephen!!
Why I never thought of this, or Louis never thought of it, I have no idea. I guess we were fixated on PST files and forgot about IMAP, since it is so new within GMail.
Update: Actually, when you copy email this way, GMail stupidly timestamps it with the time you copied it, instead of with the actual times in the email header, just as with SMTP delivery methods. So copying emails from 2002, they show up as new, sort as new, summary timestamp in list views is new. Only once you click through to the message can you see the actual date and time.
Hopefully GMail will fix this. Until then, POP3 seems to be the only way to get something into your GMail account and have it sort and summarize the timestamp property.
Update2: Based on the second comment from Stephen Foskett in this thread and some workarounds/fixes I read about in the GMail Google Group, I am hopeful I can get this working in the next few days. Jamming at work right now, though.
Saturday, November 24, 2007
GMail import from PST, mbox - my scheme
Get-rich-scheme: Make a website where people can upload their old Outlook .PST and Entourage/Netscape/Etc. mbox files. Then the site transfers the emails to their GMail account via POP3. Charge per GB or something.
(Second in a series.)
RSS killer feature - Replies, via in-reply-to element
RSS feeds would be so much cooler if items could declare themselves to be "in reply to" other items or URLs.
This would allow the following awesome features:
- Discussion threads within your RSS reader
- A "find all replies to this post" feature in your Web browser or RSS reader
- A "hide all replies descending from this post because I am SO TIRED of this topic" feature in your search engine or RSS reader
- A reduction in anonymous comment flames, since this improvement to RSS feeds would encourage people to post replies to their own blogs under stable identities they invest in
We just need an RSS extension and namespace to hold the element, which would probably be called "inReplyTo" or something like that, and of course would exist at the item level. If the extension namespace were, say, "threading," a couple of related RSS items in the same feed might look like this:
<item>
<title>Drupal development full steam ahead on linode</title>
<link>http://www.linode.com/forums/viewtopic.php?p=13246#13246</link>
<guid isPermaLink="true">http://www.linode.com/forums/viewtopic.php?p=13246#13246</guid>
<description>Well, I've been able to get off to a fast start here at linode. A very clean, lean and mean setup ...</description>
</item>
<item>
<title>RE: Drupal development full steam ahead on linode</title>
<link>http://www.linode.com/forums/viewtopic.php?p=13247#13247</link>
<guid isPermaLink="true">http://www.linode.com/forums/viewtopic.php?p=13247#13247</guid>
<threading:inReplyTo>http://www.linode.com/forums/viewtopic.php?p=13247#13247</threading:inReplyTo>
<description>I see that like myself, you use the GNU Midnight Commander - it sure makes setting up a server easier ...</description>
</item>
But related items wouldn't have to been in the same feed -- they could be on entirely different websites.
This whole scheme burst into my head as I was catching up on some RSS feeds this weekend and saw the following in Google Reader (click on image for full size):
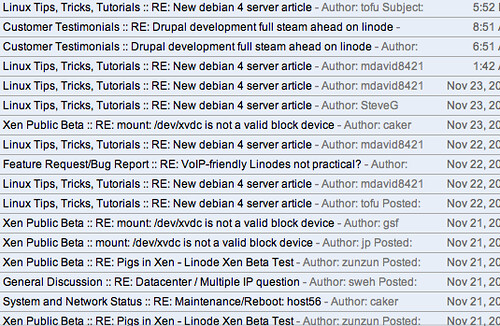
This looked broken.
See all those "RE:"s?? They are replies in the discussion forum for the virtual server I rent. I need to monitor this RSS feed for downtime, changes and upgrades to the server, but I end up drowning in all the replies, because there is no threading to hide them away.
So much else about Google Reader is broken these days. But this one actually isn't their fault. Email has had threading built in since RFC 822 25 years ago as I noted above, but RSS has nothing like it.
I looked in the spec, and the closest thing is the "source" element. But this element refers to an entire feed, not a specific item or URL. Its purpose is to "propagate credit" for the information in the item. It looks like maybe it could be repurposed for replies. Is this against the spirit of the element? I am not sure.
My guess is that inReplyTo should be its own element, for clarity. If you have people using "source" to mean "in reply to," then how can you tell when people are using "source" to mean what it originally meant, "I got this news via Feed X?" You'd have to look at what the element points to -- is it a feed or an item/web page? That takes a lot of work on the part of the reader author. Really, you'd have to do a lot of fetching.
Also, I can envision a scenario where you'd want to use both "source" and "inReplyTo" -- I find out about "Post Z" from Daring Fireball, so I put the Daringfireball feed URL as "source," but my post is a big rebuttal to "Post Z" so I put the URL (or guid) for "Post Z" as "inReplyTo."
Anyway, I also skimmed the RSS extensions to see if this showed up anywhere and never saw anything like "inReplyTo." I thought maybe the Trackback extension would have it, but that's all about pinging. Nothing really in Dublin Core ("relation" I couldn't quite figure out). The Comments extension is just that -- all about comments to a post, not posts relating to one another.
I'm really not sure how to get this going. Obviously, I can't force all the blog software hackers to add this to their tools, and then force all the authors to add this info to their posts, and then force all the reader hackers to add threading to their readers.
I do have a sort of RSS generation tool written in perl that I could use as a filter to add inReplyTo to my discussion group feeds. But I don't want to go back to hacking on my custom feed reader, I like the goodness of Google Groups .... Maybe the RSS filter could mash each thread into its own ginormous item, so it would work in Google Reader.
Some day when I have more time, I suppose.
Update: This was discussed for the Atom feed syndication format, but it doesn't look like it showed up in the (draft?) proposal. One alternate possibility would be to do <link rel="http://inreplytoforfeeds.org/inReplyTo">http://foo.bar/meh</link> in Atom feeds. But I'm not sure having multiple link elements would be allowed under the RSS2 spec, and it's certainly not common in the wild.
Also, someone drew up a threading module for RSS1, but RSS1 is not in common use in the wild anymore, most people are building on RSS2 or Atom.
Sunday, November 18, 2007
Apple decides I can't buy music
I went to buy the new Manu Chao album on iTunes. It turns out I can't buy it.
My computer can buy songs on iTunes, as long as they are locked to my computer using a complicated "DRM" system.
And until recently, my computer could also buy simpler song files through iTunes, the kind without DRM.
But now Apple has cut the price on those simpler song files, and apparently the only software powerful enough to deal with the INCREDIBLE complexity of a price cut on plain digital files needs Windows XP or Windows Vista, Windows 2000 is no longer good enough, even though it could handle the older complicated DRM files.

So if Apple wants to cut prices, it has to release a new version of its software, a new version so much more complicated it is incompatible with an entire operating system that ran the old version.
I've bought 115 songs through iTunes on this computer, and now that the files are getting simpler and cheaper, suddenly my computer's not good enough.
There's something deeply wrong with that.
Hey Apple: Thanks for making my brand new iPod so much less valuable!
7 suggestions to improve Google Docs
I've been using Google Docs to expand and revise my application for a News Challenge grant from Knight Foundation. Here are some obvious, needed improvements that leap out to me in approximately the first five minutes:
- Add stylesheets. There are certain combinations of text formatting I'd like to be able to apply repeatedly and consistently. Also, I'd like to be able to revise these styles. (Clearly, CSS should be used to build this feature on the back end. The hard part is the interface.)
- Open documents in the main window, not in new windows. It is really annoying that clicking on a document spawns a new browser tab or window. Docs should open in the main Google Docs window, replacing the Google Docs home page. It is easy to return from the Doc to the Google Docs home page should you decide to do so.
- Open a Google Groups group for Google Docs. If people have questions, suggestions or want to report problems, there is no clear central place to do so. If you click around enough in the Help pages you may be able to submit a question, but no one outside of Google can see it, and traditionally one does not expect a quick answer, or any answer at all, when making such an inquiry to Google. Blogger has a Google Group which provides a nice support function, allowing users to help one another, determine when a particular problem is widespread, and vent frustration.
- Backups. Allow them. There is no way to back up all your Google Docs. Other Google services lack comprehensive backup options, but most provide workarounds: GMail can be mostly backed up using POP access and Contacts export; Google Reader subscriptions can be backed up using OPML export; Blogger blogs can be backed up using the FTP publishing function or using Web spider software. There is no such workaround for Google Docs.
- Combined GMail-Docs search. It would be really cool if I could search my GMail and Google Docs simultaneously. If I could do this, I could keep my interview notes in Google Docs, which has revision tracking, instead of in the Drafts folder of GMail. I don't do this now because I don't want to have to run multiple searches to check email and voice interviews. If this combined search also searched my Google Reader items, all the better. Ditto with my Blogger posts! If I could customize what it searched, even cooler still. PS, I want to preserve the ability to only search email or only search docs, etc.
- RSS feeds to monitor shared docs. When someone modifies a Doc I share with them, or shares a new doc with me, it would be cool to get this info via RSS feed. Even cooler to have the option of turning off email notifications (which I'm pretty sure I only get for newly shared docs, not modifications to existing docs). Even cooler to be able to specify the granularity of what goes in the RSS feed (or to pick among feeds of varying granularity). Cooler still to be able to ovveride these settings (or add feeds) for specific docs.
- Unlame your blog. Right now the Google Docs "team blog", linked from the help pages, contains one entry dating to September, which consists entirely of a link back onto itself. [Update, Nov. 25 2007: The old lame blog, google-d-s.blogspot.com, now redirects to googledocs.blogspot.com, which looks like it has been regularly updated for some time now. Not sure why they didn't link to this blog in any of their help docs! They must have linked to it from some general Google Blogs directory or something, otherwise I don't know how anyone would have known about it.]
(With apologies to Louis.)
Friday, November 16, 2007
Google Reader is a slow, limpy, sedated way to read news
So I subscribe to the feed containing this item, and 46 minutes after it was posted it has still not shown up in my Google Reader account. I only found out about it through a Google News alert RSS feed.
Last week I noticed big delays with other sites in Google Reader.
Perhaps I'm extra sensitive to this because the reader I used to use, which I wrote myself in Perl and which ran on my own server, checked every single feed every single time you brought it up, using conditional HTTP GET requests. I was *never* getting anything other than the latest news from all my feeds (though I did consider inserting code to limit checks to, say, no more than one every 10 minutes).
If Google doesn't have the server resources to fetch feeds on demand so they are never more than 15 minutes out of date, it should create a browser plugin allowing us users to fetch the feeds ourselves on the client side.
Friday, November 09, 2007
Where is Flickr for your MP3s?
Whatever happened to online music lockers?
The free version of GMail now offers nearly 5GB of data storage, as much as my $150 iPod.
Meanwhile, Apple is selling more and more unrestricted music in the AAC format. These songs are not tied to a particular computer, unlike the songs that used to be sold through Apple's music store. And Apple recently cut prices, making unrestricted songs as cheap as restricted songs.
So why hasn't someone built a website where I can upload all of my music files and listen to them from any computer? At work, on my wife's laptop, in a hotel, etc.
The infrastructure is cheap. In fact, it's so cheap, I'd gladly foot the storage bill myself. Amazon now charges just 15 cents per month to keep 1 GB of data on its Web servers. Add in the cost to upload that data, and you're talking about $15 for the first year to dump the contents of my iPod onto the Web (falling to half that for subsequent years, since the music is already uploaded).
A smart company could probably offer the service for free and make money interspersing audio ads with your music. Or make online storage of unrestricted music files a premium upgrade to an existing product.
Bear in mind that I'm talking about music storage, not music sharing. Aggressive interpretation of copyright law is what doomed the original MP3 locker, my.mp3.com, seven years ago.
I reserved tunesr.com for just such a service, but amid my other projects have not made much progress on it.
Tuesday, November 06, 2007
Google Reader delivers news like a snail
Right now Google's RSS reader is lagging
- Fake Steve Jobs - 4 posts
- Daring Fireball - 2 posts
- Eater SF - 2 posts
Google has a great news reader, as long as you don't expect your news to be, well, new.
Tuesday, October 09, 2007
Steal This Checkbox News - CityPipeline.com
Last month I entered a grant competition sponsored by the Knight Foundation, called the News Challenge and designed to bring traditional news into the future.
In the middle of my first honeymoon week in Paris, they now tell me my application has advanced to the next stage and gone on the Web along with a bunch of other applications. Great news.
My idea is a map and news hub on local real estate development, easily customizable. It's called CityPipeline and is based on ideas I stole from other people, ideas you too should steal :-)
Checkbox News
 From Dave Winer, I stole the idea of Checkbox News (see also).
From Dave Winer, I stole the idea of Checkbox News (see also).
With Checkbox News, you can instantly and easily customize your view of the news, without creating an account or otherwise leaving the page. The mockup in the image at right tells the story well.
I wanted this at CityPipeline. Traditionally, people who care about real estate news get it all bundled together. The newspaper I work for, the SF Business Times, does not let you filter by topic like Checkbox News. So if you only care about hotel and restaurant real estate, or only residential, or only retail, too bad, you get it all. If you only care about news in your neighborhood, too bad, we cover five counties!
 For CityPipeline, I made checkboxes that instantly filter the database by type of project (residential, office, hotel, retail, restaurant etc), stage in the pipeline (no problem to only see news on projects under construction or approved by city government), date and, eventually, more. We automatically remember what is checked and unchecked when you come back to the site. You can also center the map on any address and zoom in and out, and we remember that too.
For CityPipeline, I made checkboxes that instantly filter the database by type of project (residential, office, hotel, retail, restaurant etc), stage in the pipeline (no problem to only see news on projects under construction or approved by city government), date and, eventually, more. We automatically remember what is checked and unchecked when you come back to the site. You can also center the map on any address and zoom in and out, and we remember that too.
Eventually, I'd like to have RSS feeds and email notifications based on proximity to an address (home or work, usually) and the other filter criteria.
The news is a platform
The bigger idea I stole from Dave was to try and make my news site (someday, if I'm lucky) into a Coral Reef, complete with its own API.
 The smart news publisher knows he is not a publisher so much as a platform vendor. On the Web, his readers are his competitors (they publish too!) and his competitors are his sources (thanks to the hyperlink). It's the sort of complicated relationship Microsoft had with other software companies and that Google now has with other Web publishers (including newspapers).
The smart news publisher knows he is not a publisher so much as a platform vendor. On the Web, his readers are his competitors (they publish too!) and his competitors are his sources (thanks to the hyperlink). It's the sort of complicated relationship Microsoft had with other software companies and that Google now has with other Web publishers (including newspapers).
So to win today, the smart news publisher creates a kickass API to all his news. He becomes the most efficient and trustworthy conduit of information.
He lets other people steal his data (which was never really his data in any sense, including legal or ethical or practical) so they will give him their data. They will flood him with their data -- news tips, links, stories -- when they see they can easily get their data our of his site, and when they see that plugging data into his site routes it to the right people, quickly.
 This is how news has always worked, since the first days of print and probably before, it's just that now you need to know how to program to make it happen, and news companies just suck at software right now. And as the oldest of old media, they also come from a culture that is too closed and hierarchical.
This is how news has always worked, since the first days of print and probably before, it's just that now you need to know how to program to make it happen, and news companies just suck at software right now. And as the oldest of old media, they also come from a culture that is too closed and hierarchical.
Even in prototype form as submitted to the Knight Foundation, CityPipeline lets and explicitly encourages anyone basically slurp the entire database as a giant XML file. Since I'm trying to get people to submit real estate data into my site, including links to news and blogs and raw information on real estate developments, I have a selfish reason for doing this. You should too!
In my grant application for CityPipeline, I outline other ways I'd like to make CityPipeline into a platform, including by adding an API (which could be used to add, read, search and list projects and associated news and documents) and by adding RSS feeds (for individual projects, the map as a whole and by category).
Subscribe to:
Posts (Atom)