Wednesday, December 09, 2009
C as a death monster (and Ruby as a companion demon)
Posted over on my Tumblr (an extended quote from Coders At Work)
Saturday, August 15, 2009
Why real-time RSS is a big deal for big payloads, too
I'm very much interested in emerging Web publishing ping systems like Google's PubSubHubBub and Dave Winer's rssCloud. I call these systems "real-time RSS" for short, since they basically allow syndicated content ("RSS") to be delivered at Twitter speeds ("real-time").
I've noticed a focus on using these systems to replicate Twitter, but think the opportunity for publishing bigger-than-Twitter content is just as exciting.
Why I'm kind of obsessed with this:
I've noticed a focus on using these systems to replicate Twitter, but think the opportunity for publishing bigger-than-Twitter content is just as exciting.
Why I'm kind of obsessed with this:
- As an RSS consumer, fat-content real-time RSS could improve my ability to read blogs. I read hundreds of feeds for my day job, via Google Reader, the best RSS aggregator available. Some of the most essential feeds are updated within Reader only sporadically, hours after the originating feeds have updated, literally making me worse at my job (timely blogging). Real-time RSS systems promise to solve this problem (Google Reader is already starting to implement these systems.)
- As an RSS publisher they could improve my ability to reach readers. I don't have a technical role at the blogging company I work for, but I've advocated real-time RSS as a way to reach our readers faster, and to stay competitive with other publishers. Frankly, I'd love to see our feeds updating fast in Google Reader, because they come pretty slow at the moment, in giant clumps covering hours, and I don't want other sites gaining a big lead.
- As a technology observer, I'm curious to see whether the split between Twitter-like, 140-character-or-less implementations of real-time RSS and "fatter" uses of the systems can be resolved in an elegant and constructive way. "Let's just duplicate Twitter" seems way too constrictive a way to view these systems from where I sit; on the other hand, the less ambitious approaches are the ones that tend to be simpler, and thus "win."
Tuesday, April 21, 2009
If someone can take one of our fonts, put it in a freely accessible directory on their server, that’s a violation of most of our license agreements. We’re going to have to spend a considerable amount of time trying to catch this when it happens.
Welcome to the world of every other creative professional in the world, Tal Leming. Typographers do not get special, W3C sanctioned DRM. Sorry.
Monday, January 19, 2009
Features Safari should steal from Firefox
A companion piece to "Features Firefox should steal from Safari." (Follow link for the backstory.)
- Remember last tab(s) closed (Safari only remembers last window closed)
- A tab menu, listing all tabs (Safari will list tabs that don't fit into the window, but it's better to have something that lists all tabs, since tab titles are usually truncated)
- The Awesome Bar
- Search within form textareas
- Scrolling tab bar that animates when you pick a distant tab out of the tab menu
- A clear target on which to drag URLs to make a new tab when a window's tab strip is full of tabs (in Firefox you can drag onto the New Tab button or the tab menu; in Safari you have to divine the location of a tiny strip at the end of the tab bar, immediately to the right of the last tab, and invisible when the rightmost tab is not active)
- Option to drag bookmark into bookmarks bar folder without fussing with the title of the bookmark -- much faster.
- Quick Search shortcuts to search alternate/custom sites via URL bar (or build in something like Inquisitor)
Features Firefox should steal from Safari
I switched from Firefox to Safari about 6 months ago due to frequent crashes in Firefox 3 RC 3 . Now I'm switching back due to a longstanding unfixed cookie bug in Safari (see also).
This post is a journal of Safari features I wish Firefox had. I'll be updating it for a month or two.
(I am on a Mac. Also, I spend 10+ hours per weekday in my browser, blogging, and I use the Web for my email and RSS reading -- I push the browser pretty hard, but also use certain features a lot more than the average person.)
This post is a journal of Safari features I wish Firefox had. I'll be updating it for a month or two.
(I am on a Mac. Also, I spend 10+ hours per weekday in my browser, blogging, and I use the Web for my email and RSS reading -- I push the browser pretty hard, but also use certain features a lot more than the average person.)
- Remember last window closed (Firefox only remembers last tabs closed)
- Don't reload tab when dragging it to another window
- Remember tab history after dragging it to another window
- Drag tab into its own, new standalone window
- A nice long History menu, with lots of items, and submenus for "Earlier today" and past days. Firefox is showing a measly 10 items by default, then you have to open a new window to get more. (Sure, there's probably an about:config setting, but still)
- Ability to correctly print Web pages without, for example, constantly and bizarrely and silently disappearing more than half the text
- Preview pages right in the print dialog
- Easy-to-read search-within-page results (Safari dims all text except instances of search string. First result highlighted/magnified; other results also highlighted, but less so. And when possible it centers screen on search result. By default, firefox only shows first result, with no dimming, and you have to Find Again for other results. Sometimes it doesn't seem to find the first result on the page -- searches from where the invisible "cursor" is?)
- Right click option to "download link" or "download image" without having to specify save location (uses default download location, usually Downloads folder)
- Fix bug preventing me from dragging links rendered by Google Reader into bookmark bar folders
- Stop showing annoying "This site does not supply identity information" tooltip when I'm just trying to drag the URL bar handle into a bookmarks bar folder. It sometimes blocks the folder!
- When remembering username/password for basic HTTP authentication (the kind that pops up a browser dialog with username and password fields), automatically submit the credentials, don't ask me to click "OK" each time. Safari is so good at this I had forgotten it was doing it.
- Option to prompt for new bookmark title immediately after dragging URL into bookmark bar folder (shift-dragdrop?) (Safari does this by default, with no option to NOT be prompted for a new title; that's annoying and slow, but I like the idea of it as an option)
- Keyboard shortcuts for bookmark bar bookmarks (Safar does Command-1, Command-2, Command-3 etc.)
- Drag file onto standard file upload form control (fills in control with file's path)
- Animate tab reordering (am surprised I miss this)
Thursday, December 04, 2008
Google Reader Redesign Misses Something

Google is asking for feedback on the redesign of its "Reader" RSS aggregator.
Here's some: It's still too hard to assign feeds to folders -- the names of the folders get truncated in the Feed Settings menu. See image at left.
The menu should expand to accommodate the names, with a much larger maximum width.
This is still my single biggest design issue with Reader.
I'm also curious to see if they fix the technical issues, like misreporting old feed items as new, and very slow updates for some feeds (i.e. Google's servers don't fetch the feed often enough).
UPDATE: Same thing with the folder list in the left sidebar, see below. And there's no way to make this wider:

Saturday, August 30, 2008
Macs suck at fonts now?

Just spent an hour trying get my damned Mac to install a font. The system is smart enough to identify both the PostScript and TrueType files as fonts in the Finder -- and it even loads a preview! But try to "Add Font" in the system's Font Book application and you get a SILENT failure.
No dialog. No diagnostic message. And no font added.
UPDATE: I'm not the only one with this problem. A known bug. No response from Apple.
UPDATE2: Just add the files to ~/Library/Fonts. Works fine that way.
Wednesday, August 27, 2008
Mac OS X Fails Me Every Damned Night
Right now I'm watching Bill Clinton's DNC speech for about the fifth time, because OS X has yet again crashed. This time, in the midst of a video capture.
You think you know your operating system? Trying using it for 12 blog posts a night. With video capture and editing and encoding and uploading. Heavy picture downloading, cropping and scaling. Heavy RSS skimming across hundreds of feeds. Heavy Web surfing. Streaming in lots of video. Heavy email use. Constant IM. Ten different things going on at once in the name of speed on a busy news night.
You'll discover how weak your tools really are, even when they're the best the world has to offer. Not just the OS but your Web services (Google), third-party software (ecto, Photoshop, Visual Hub, SnapzPro) and Apple sofware (iMovie, Preview, Safari, iChat).
They will break your heart and, worse, waste your time night after night. It doesn't matter if it's a brand new multicore machine with the RAM maxed out. It doesn't matter if it's built on a Unix core that's supposed to have protected memory and preemptive multitasking. OS X WILL have a hard crash on you sooner or later. In my case, it happens once or twice every night.
Every crash sets me back a half hour or so. That's time out of my life and it adds up.
Hard things are hard to do. Fair enough. I didn't build a better system. But I hope Apple realizes how fragile its system is at publishing, 21st century style.
Saturday, August 16, 2008
Del.icio.us ruined as professional tool
A note on the new version 2 of del.icio.us: We actually use it extensively at work as a professional tool, to share links with one another (and thus to suggest or assign posts and various other things). However v2 dropped timestamps on all bookmarks -- only dates are provided. This has made it about half as useful. And there's not even an option to turn timestamps back on!
Lesson: If your design assumes people will use your app as a kind of casual toy, you will probably foreclose serious, hard-core use.
Thursday, July 31, 2008
Drawing A Circle In Photoshop Elements: PhD Required

Even with these directions, I couldn't make it work. And Barbara Brundage/Dave Pogue/Tim O'Reilly's "Missing Manual" isn't helping either. What a waste of money this program has been.
Sunday, July 06, 2008
iPod weak for podcast listening
Hey iTunes: If I'm halfway through an hourlong podcast, please don't delete it off my iPod because you think I'm done with it. If you're going to monitor what I listen to, at least do it right. Right click/mark as new + resync is getting really old.
One day, Apple will learn to make a reliable MP3 player
My iPod freezes multiple times per week. (Most recently, five minutes ago, as I tried to rest after a night of paperwork.)
I use it strictly to play music.
Some day, Apple will learn to make one of these portable music thingamajigs that doesn't crash. They just need some more time to iron out the kinks. They've only had seven years so far.
The attached image is a Google search showing how common this problem is. The second hit is from 2004, The third hit is an Apple doc on the topic, linked to a movie they made on the topic.
I use it strictly to play music.
Some day, Apple will learn to make one of these portable music thingamajigs that doesn't crash. They just need some more time to iron out the kinks. They've only had seven years so far.
The attached image is a Google search showing how common this problem is. The second hit is from 2004, The third hit is an Apple doc on the topic, linked to a movie they made on the topic.

Saturday, July 05, 2008
iTunes sucks at importing burned CDs
I've been cleaning out my physical home office inbox, and importing to my Mac a bunch of mix CDs given to me by other people. Every time, iTunes asks if I'm sure I want to import a CD that's not in CDDB or whatever it's called these days (Gracenote?). Uh, yes.
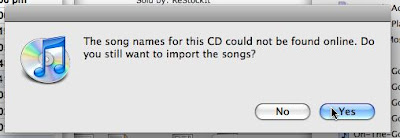
When I click "Yes," that would be a good time for iTunes to ask me to name the album. Instead, it doesn't, it just starts importing the CD, so I end up with a bunch of tracks named "Track 01" "Track 02" etc. and with blank album names. So I can't tell apart one imported CD from another and the tracks become lost, one mix CD indistinguishable from another.
The workaround, by the way, is to select all the tracks on the CD (don't wait for them to be imported, this works with an import in progress), select File/Get Info, say "Yes" to the scary confirmation dialog, then enter the name of the mix into the album field and hit "OK." Now you'll be able to pull up the mix CD just by typing the name into the iTunes search field while browsing your music library. If you feel like naming the tracks, you can do that later, whenever.

When I click "Yes," that would be a good time for iTunes to ask me to name the album. Instead, it doesn't, it just starts importing the CD, so I end up with a bunch of tracks named "Track 01" "Track 02" etc. and with blank album names. So I can't tell apart one imported CD from another and the tracks become lost, one mix CD indistinguishable from another.
The workaround, by the way, is to select all the tracks on the CD (don't wait for them to be imported, this works with an import in progress), select File/Get Info, say "Yes" to the scary confirmation dialog, then enter the name of the mix into the album field and hit "OK." Now you'll be able to pull up the mix CD just by typing the name into the iTunes search field while browsing your music library. If you feel like naming the tracks, you can do that later, whenever.
Amazon's feedback loop sucks
Speaking of the ways in which Amazon sucks, I have probably spent upwards of $2,000 on that site so far this year. I wanted to send them feedback (a few months ago) about the ridiculous amount of packaging they use, which not only fells trees but takes up wayyy too much space on trucks and planes thus contributing to global warming.
Same thing tonight, I wanted to bitch about the product "In Stock" lie.
They really don't want to hear feedback from customers. Nothing you can find on the site, no form, no email address, nothing.
Same thing tonight, I wanted to bitch about the product "In Stock" lie.
They really don't want to hear feedback from customers. Nothing you can find on the site, no form, no email address, nothing.
Amazon's crappy checkout design
No, the checkout would be the wrong place to tell me your partner store is entirely out of stock of what I ordered, Amazon. Thanks for wasting my time.




Subscribe to:
Posts (Atom)